Our builds include a basic model that has decent speed and accuracy but not a big size. (You can think of the model as the brain.) You can download a bigger and better better brain (model) in ggml format and configure it in the Speech to Text dialog, but it will be slower.
The dialog creates two jobs that appear in the Jobs panel: one to export audio and another to convert to text. The results are added to the Subtitles panel as a new top-level Subtitle Track.
Currently, the only GPU our build supports is Apple Silicon. Otherwise, it is heavily multi-threaded on the CPU.
Known Quirks:
Subtitle items sometimes start earlier than expected. Timing is provided by the model and tool, and we lack the skills and resources to improve this.
Expect there to be occasional errors. Like humans and non-ideal conditions, it is not perfect. We will not take action on bug reports about some piece of audio not converting to the expected text.
OpenAI has made some warnings about the usage of their Whisper models:
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent… We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes.
when i run detect spech to text for subtitle, my job field and this is the log from field job whisper_init_from_file_with_params_no_state: loading model from 'C:/Users/W1985RL/AppData/Local/Programs/Shotcut/share/shotcut/whisper_models/ggml-base-q5_1.bin' whisper_init_with_params_no_state: use gpu = 1 whisper_init_with_params_no_state: flash attn = 0 whisper_init_with_params_no_state: gpu_device = 0 whisper_init_with_params_no_state: dtw = 0 Failed with exit code -1073741795
It is not on GitHub. You need to click the download link in the documentation above. From there, look for the row you want choosing only .bin files, and click the down arrow icon in that row to download it. You do not need to download all of the files.
I do not know, and it depends. You can search the web for people who have studied whisper models across various types of content and languages.
Try ggml-large-v3-turbo-q8_0.bin
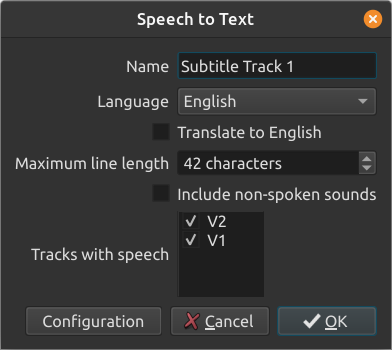
In the dialog, the “Language” selection helps the speech detection engine do a better job. The speech detection might still work if you choose the wrong language, but it might not be as accurate.
The engine only supports translation to English if you choose “Translate to English”. It can not translate to other languages.
Hi. I want to create a modern subtitles animation with a style of my choice. At the moment, I have two options: “Burn in Subtitles to Output”, I can customize the style of the subtitles throughout the video, but in this case I can’t do any animation. If I use the “Generate text on Timeline” option, the subtitles are divided into separate elements, each of which I can edit and do whatever I want, but in this case I have to manually change the “text:simple” filter settings in each element, and there can be a lot of them. My question is: is there a way to pre-set the subtitles style before I click “Generate text on Timeline” so that they are generated with the font I need, in the right place? For example, it would be convenient if I could customize the style in the “Subtitle BurnIN” filter, which would be applied to the “Generate text on Timeline” option. Is it possible to do this? Thanks in advance for your reply and thanks for the opportunity to make subtitles.
For the next release, I have added a dialog to prompt for a text preset when generating text subtitles on the timeline.
With this feature, you can use the text filter to create a preset with the style that you want. Then, when you generate text on the timeline, you can choose that style and it will be applied to all subtitle text items.