Yes, yes, you are happy, but I have the work!!! Remember, I’m 67 and learning has never been particularly easy for me - it takes me a long time.
However, you never complained about the work we questioners give you either.
Can you process the projects from Kdenlive in Shotcut?
If letter spacing for the titles is added now, there’s nothing stopping me.
Wow! I hope I can keep up with technology at age 67 as well as you are doing! Nobody I know around me in that age range is able to use a video editor without having prior professional experience.
In regards to using Kdenlive projects, I don’t have any knowledge in that area. I remember that you wanted to do your entire workflow in a single program, and that’s reasonable. For me if I was in your shoes, I might be tempted to make titles in Kdenlive and export them as videos, then bring those videos into Shotcut and finish the project there. There is still potential to make quick color changes directly on the title videos using the Hue/Saturation/Lightness filter or the Color Grading filter, without having to go back to Kdenlive to edit and re-export another video. Or, maybe the titles could be done last so they can be guaranteed to work on the first try? With some creativity, I think you could have the best of both worlds.
Sometimes it gets a bit much for me, all the things I have to learn. Consider: 30 years of Windows and 10 Vegas Pro for video editing. But a year and a half ago I switched completely to Linux. It was and is an adventure - but I wanted it that way. There first Cinelerra GG: Absolutely exotic, I had some fun with it, but it is hardly developed further and has a totally different, very old approach. It is not possible to combine audio and video tracks. If you’re not careful, then nothing is in sync. Unimaginable to work with it in the long run. Then Shotcut, over a year ago. Wasn’t stable enough for me and had neither compressor nor EQ at the time - so a no go. Then, as you know, Kdenlive. I got to grips with it very quickly. But there are some important things missing and the error in color grading (lift/gamma/gain) which obviously doesn’t bother anyone! Unbelievable. And then, the very big difference: the forum!!!
Your tip with the titles - I will not do it that way. For me it’s all about the content of my videos, I don’t need all the effects. I’ll see if I can find a font I can handle and then I want to stick with one application. I’ll make the switch slowly and then we’ll see how it goes.
Can I count on the Equalizer: Parametic to come in the stabel version for sure?
So, that’s enough now. I’ll certainly ask you to help me improve my voice with Shotcut, but I’d better open a new topic later, not today.
I’m sure that thanks to all your remarks my small yt channel will be much better at least in audio area. When I publish first video with “new audio”, I will let you know. I have plans to divide my channel into two (English and Polish separately) and would like to profit from that split at the same time improving my old videos (as I have to upload them once again).
I did some additional experiments according to your suggestions but finally I decided to keep version C. If it’s ok for you, I’m sure that it will be more than perfect for 99% of my visitors. I didn’t hear any special difference when doing experiments but it can be also related with not enough good audio equipment.
Btw, if you are 67 years old, I’m even more impressed. You are keeping extremely well and I’m very very impressed. I would like to know so much about audio processing as you!
Hello @ken_wawa, hello @Austin @,
now I have discovered my big mistake:
You can’t replace a low cut filter with a low shelf!!! I did that wrong with all my videso and now with the processing of ken_wawas audio. Low Shelf (= High Pass) takes away too many frequencies, even above the set value. This makes the voice sound too thin after all. (I will now revise all my videos again).
But your ability to doubt my suggestion and especially Austin’s patience have now moved us both forward decisively.
Many thanks to both of you.
Micha
Yes, it is tremendous what you and I and everyone else can learn on the forum as well and especially from Austin.
And, not to be underestimated: Shotcut itself! I am totally amazed at how well the audio filters work. Could it be that @Austin had a hand in that? A good 18 months ago, I had been looking around for a video editor as an alternative to Vegas Pro. Shotcut was very unstable on Manjaro Linux, I had crashes all the time. To me the audio tools were the most important thing and at that time Shotcut didn’t have a compressor and EQ - you can’t do it without. So Kdenlive was clearly ahead. Today I have to realize that my assessment is completely turned upside down. Painfully I see that with Kdenlive the compressor is bad, that there are many EQ, but all of them are not satisfying and that there is no audio loudness. Now this discussion has piqued my interest in Normalize: Two Pass. And to my great horror I experience: It doesn’t work in Kdenlive either (bug)!
What do I have to do now? I have to get used to Shotuct’s timeline. I have the impression it is very imprecise. I really hope that I will manage to work with it.
Postscript:
Have no more problems with the timeline: I just had to turn off the three Ripple functions: Now I can work quite precisely. And sometimes I have to turn off snapping when I want to shift very finely. Everything ok with the timeline.
@brian has made many audio tools in Shotcut, including the LUFS loudness meter and the recent EQ interfaces. I haven’t contributed any audio-related code yet. So the biggest thanks goes to him that we even have these tools available.
You guys are really driving me crazy!!! Why does Shtocut put so much emphasis on good audio tools? Who can still resist?
If I follow your order of tools - does it matter in which order they appear in the program or just when I apply and set which filter?
I would like to take my first serious steps and ask you to look at the audio filters. Should I attach my questions and examples here or open a new discussion?
I could put the original files on filelbin or should I rather upload the file as mp4 and the mlt here?
Question: Do I need the limiter if I have only one audio track and have previously applied the “Normalize: Two Pass”? Doesn’t this also prevent clipping for sure?
Question: What value should I choose for spoken language? To me -17dB already seems pretty loud.
Question: Where can I find information about the “Audio Loudness” scope?
Both orders can be significant. It also depends on personal preference, since it is technically possible to get [near]-equal results with a variety of filter orders. This is described in the first part of post 40 above:
As for the screenshot of your filters, the only question mark I see is placing the limiter before the EQ. The purpose of the limiter is to prevent clipping. To do that, it needs to be last in the chain. Otherwise, any filter that comes after the limiter can raise the volume and produce clipping. This is why the limiter is normally placed on the Output track rather than an individual clip. The limiter has a chance to squash all spikes from that position.
Unfortunately, “Normalize: Two Pass” does not prevent clipping on its own. The only thing Normalize does is find the average volume, and change the Gain of the clip so that the average volume will match the configured target.
Example: If Normalize decides it needs to raise the Gain by +10 dB to make the average volume match the target volume, then boosting 10 dB has potential to send the spikier parts of the waveform through the 0 dB ceiling. Normalize does not do any dynamics compression or peak reduction. There are specialized filters like Compressor for that purpose which offer more configuration options. Normalize blindly raises or lowers the volume of the entire clip to match a target without any regard for the consequences. This is why it’s good to put the Compressor first… to control the spikes before they get boosted through the ceiling by Normalize. This is also why it’s a good idea to keep the limiter even for one track, because Normalize does not do any spike control.
Podcast platforms standardize on -16 LUFS, and this is fine for YouTube as well. The tolerance is usually +/- 1 LU, so -17 would be okay.
“Loud at -17” is relative though, because someone listening to your audio may have their headphone volume turned down lower than yours, and then -17 seems fine to them. If speech seems uncomfortably loud at -17, then something else may be going on like a compressor that’s configured too strong, or an EQ that’s boosted too much on a resonate frequency that causes ear fatigue.
In that document, Program Volume (also called Integrated Volume) is the “I” meter in Shotcut’s loudness scope. Integrated means “the average volume of every audio sample that’s passed through the meter since the last time it was reset”, which is very different than saying “since the last time I hit the play button”. Remember to reset the meter before starting a new running average! “M” and “S” are also volume, but based on much shorter intervals for spot-checking your audio. “M” averages the last 400 milliseconds while “S” averages the last 3 seconds. Lastly, True Peak is the “TP” meter.
I am learning and learning.
Your always very clear and patient help, have made me very curious about Shotcut. Now I realize that the program also has a lot to offer, few filters, but the better ones!
I still have to get used to the idea of using a compressor, the normalizer and the limiter at the same time, that is very new to me. I thought the compressor could do that on its own.
And about the limiter, a question: is there a basic setting? And, couldn’t I also detect the peaks and clippings on the audio loudness and reduce the volume manually that way? E.g. take back the gain in the compressor?
I’m also learning and learning and that makes me… a bit crazy…
@Austin Could you spend one minute and have a look on this video: 🔮 Życie za 100 lat… z perspektywy 1899 roku - YouTube It’s not in English so it might be a bit more challenging. But I’m curious what do you think here about voice quality which I improved according to your suggestions? Moreover I had quite a lot of problems with relation voice loudness and music loudness. Depending which headphones or which speakers I use this relation seemed to be a bit different. Finally I found some kind of compromise according to my ears, but I would be curious your opinion. Looking on LUFS I, it doesn’t meter if music is added or not. LUFS is the same after 1:30 minute in both cases (no music/with music), thus I have impression that LUFS show that music level is quite good then… But is that? For sure partially it’s the question of personal taste but I would be curious a lot of your opinion.
The makeup gain of the compressor can technically boost audio the same way that Normalize does. However, the question is how much boost should be done? Normalize automatically answers that question for you. Normalize is faster and more reliable than manual metering.
Most specifications like EBU and even audiobooks say there needs to be -1 dBTP of headroom preserved. This is an especially good idea for audio that’s saved in a lossy format.
Lossy compression by definition is not a perfect recreation of the original audio. So, if the original audio went all the way to 0 dB, then an imperfect lossy reproduction may try to go over 0 dB. This means that audio samples that were almost 0 dB in the original are now flatlined at 0 dB due to lossy approximation, and the amount of clipping distortion can be significantly increased compared to the original audio. If there is -1 dBTP of headroom, then even a poor approximation of the original audio can be represented without hitting 0 dB, which avoids the chance of clipping distortion due to encoding.
In Shotcut, I usually set the limiter to -1.5 dB because Shotcut’s limiter works on Peak values as opposed to Reconstructed True Peak. For speech-only audio where transients are pretty tame, a setting of -1.0 dB is probably fine. The -1.5 dB is for music that has percussion elements and sharper waveform spikes.
Technically it’s possible. But it would be necessary to review the entire audio track by eye to find the amount of reduction the compressor needs. If it’s a five-minute track, that’s five minutes of your life sitting there doing nothing but looking at a meter, trying not to blink. The benefit of using compressor + normalize + limiter together is that they can make any length audio track become pretty loud pretty quick without a lot of thinking or manual review.
Yes, I can see the balance being a challenge to find with that style of music. As in, the music has super-low bass and super high synths with nothing in the middle, which is a perfect slot for your voice to sit without competition. This is probably why the LUFS meter didn’t go up when music was added… there were no overlapping frequency ranges in the speech and music tracks, and the music was rather low volume.
Personally, I think you nailed the balance. The music is there but not competing to be in the foreground. Sounds great on my speakers, and also in Sennheiser HD280pro headphones.
Here too, you made it sound excellent. Very clean, not even background hiss. It sounded perfect in headphones. But on speakers, I heard some resonance that sounded almost like internal interference, and it was causing a bit of ear fatigue (pressure sensation) pretty fast at a modestly high volume. (The average person will not listen to your audio in this manner lol.)
So I ripped some audio from your YouTube link and analyzed it with Ocenaudio, which is a free but closed-source audio editing tool similar to Audacity. However, Ocenaudio provides some visualization tools that can really help find a problem.
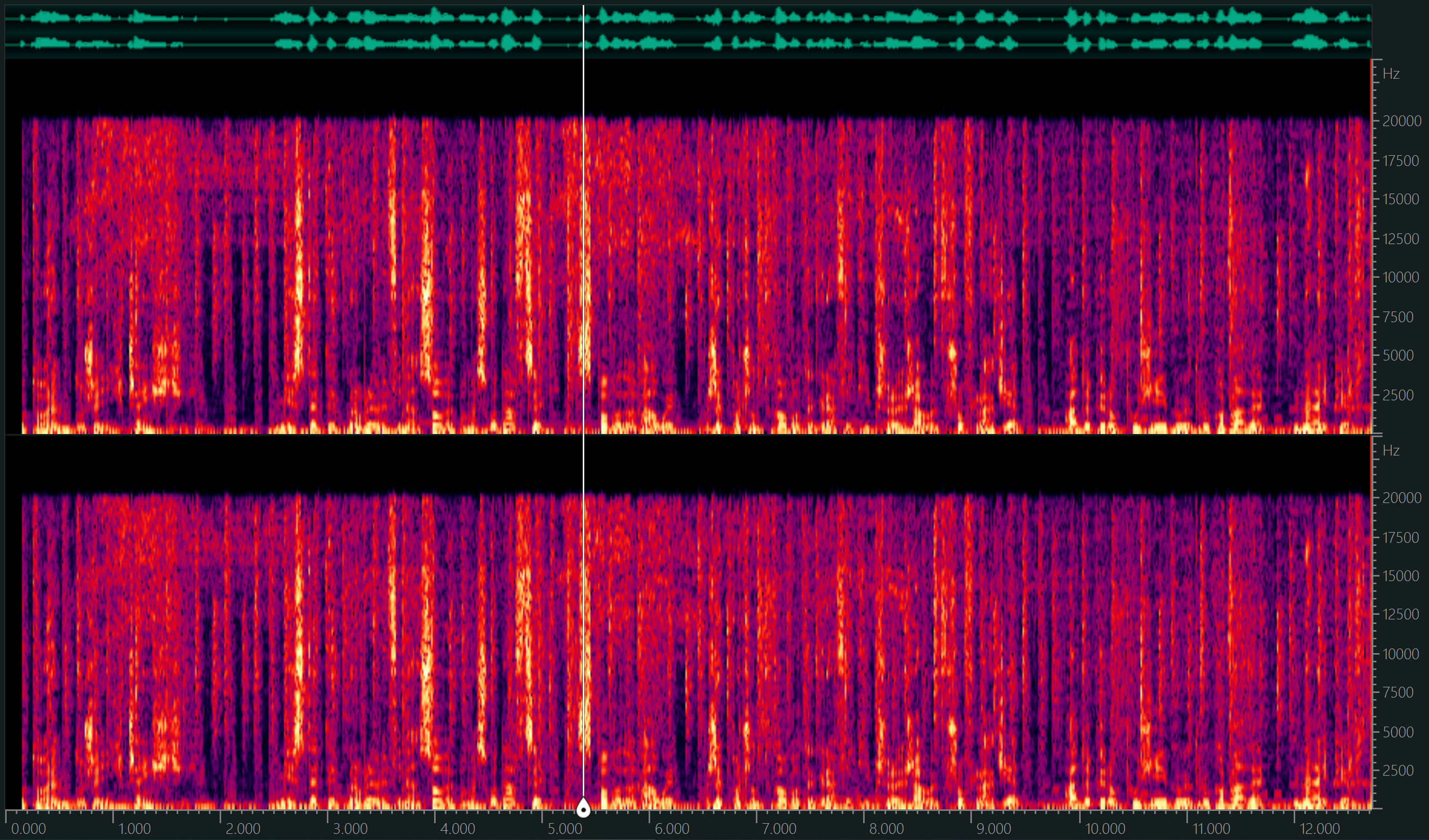
Here is what the spectrogram from your audio looks like:
The upper graph is the left channel while the lower graph is the right channel. The X-axis is time, the Y-axis is frequency. The Hertz scale is on the far right. Blue means quiet, purple is medium, red is normal, and orange is the loudest. There is a white line between the 5- and 6-second marks which shows a particularly loud part of speech, with lots of orange all the way up the frequency spectrum. This confirms the internal resonance I was hearing. To have that much activity across such a wide spectrum suggests the compressor is doing its job well! Also, we notice a thick orange horizontal line that extends the entire length of this clip at the bottom, representing some serious low bass. More on that in a second.
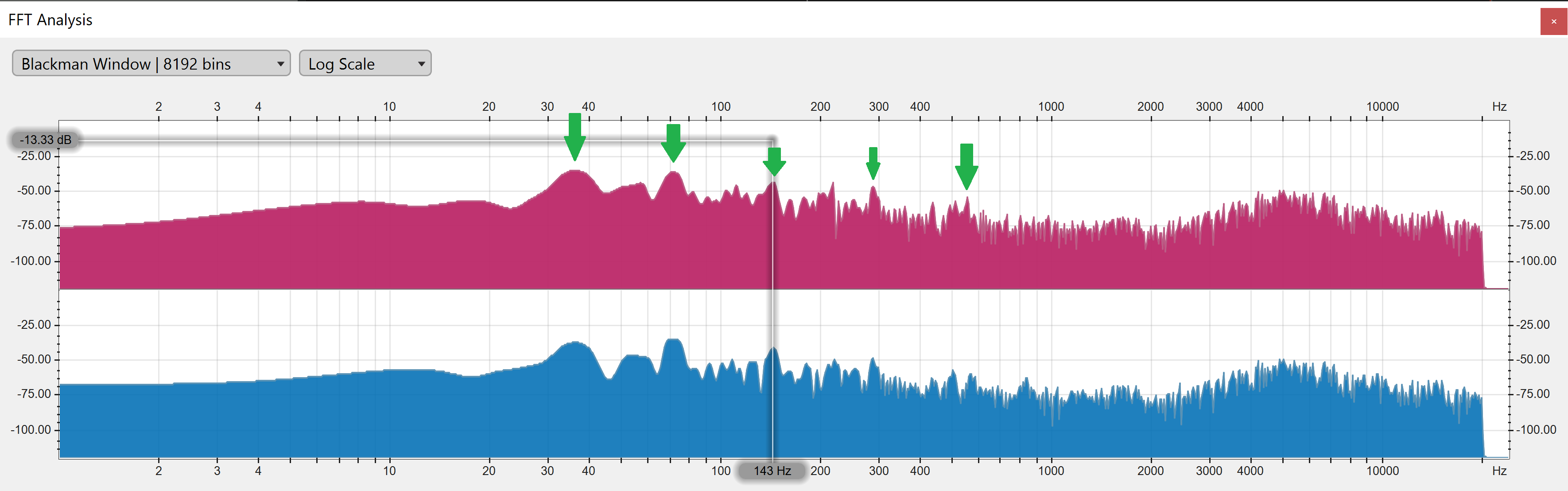
Next, I wanted to dig into that white line sample for more detail. Here’s the FFT spectrum analysis of that moment:
I marked five green arrows. Their positions are 35, 71, 143, 285, and 550 Hz. Guess what those numbers are? Every time the Hertz doubles, the sound appears to be one octave higher to human hearing. All of these swells in the frequency are factors of two from each other. This is mostly from the fundamental and overtone frequencies of your voice, all of which are relatively similar volume level as a result of the compressor (probably). The 35 Hz is coming from the thump in the music track, but is also producing an overtone at 70 and probably 140 that is perfectly colliding with your voice, causing a type of interference.
I tried the following Shotcut EQ settings to smooth it out:
Low Shelf:
70 Hz
-0.6 dB
0.5 slope
Band:
144 Hz
-0.2 dB
1.2 Q
The low shelf is to knock down some thumpiness in the music bass line. It was carrying a ton of energy at 35 Hz. The 144 Hz band is to bring down your voice fundamental to reduce the low-end hype. The hype could be partly from proximity effect on the microphone, which was then exaggerated by the compressor. It is normal for EQ adjustments to happen on the fundamental frequency of a compressed speech track.
In headphones, this EQ’d version sounds pretty much the same as your original. But on speakers, the sound is subtly smoother, less hyped on the low-end, less “up-close recorded microphone” sounding and more open-air natural sounding, easier to listen to for longer periods of time. It isn’t a drastic change; the original already sounded great. I figured you might be interested to see what a deep-dive looked like, so there it is. Even going through the microscope of an FFT analyzer, I had only super-minor suggestions that would only be noticeable in a serious listening environment.
Great sound you got there, really!
If you’re curious about making those graphs, Ocenaudio can be found here:
Quite a big help, dear Austin! You know how to describe difficult and unfamiliar issues in a very clear, easy to understand and comprehensible way.
You are a wonderful mentor and a great gift for us, for Shotcut and for all who want to learn.
We all have good reason to thank you very much. It is not a matter of course to deal so intensively with the problems of beginners and to remove so many obstacles from their path, with your knowledge and skills that you have certainly acquired painstakingly over the years.
First of all, big thank you for such a deep analyse. I learned many interesting things!
But for sure I have to limit somehow how much time I’m spending on audio and especially voice improving as otherwise I will spend the whole summer in this rabbit hole he he (in the sense that probably most of yt viewers never appreciate my effort here and I should make more videos simply… ) But still it’s so interesting to learn so much about audio processing and about my own voice.
For me it’s a bit strange story with this 35Hz and multiplied values (70Hz,…). As for voice track I cut everything below 70Hz with High Pas filter. So theoretically there should not be anything with 35Hz… I’m wondering is that possible that it’s just music recording which is causing this? It’s this music: https://www.youtube.com/watch?v=k8p6hGkdmkY
Should I perhaps lower this 5dB for 100Hz, and and instead of 1000Hz with 0 dB a new 200 Hz with 0 dB. Hover I have doubts here as I really like to have more bass in my voice. So if I reduce it, I will really miss it.
The voice on yt I really enjoy is the voice of this guy (he has very nice voice rich in bass part), please have a look (unfortunately it’s not in English): https://www.youtube.com/watch?v=vNRoy7qjWss&t=68s Although I’m not sure how much its his natural voice and how much it was modified with some filters (I asked this guy few times but he has never answered).
I’m also wondering how much it might be caused with recording too close to mic. I like to be close to mic as then I have impression that my voice has slightly nicer timbre and is more rich. But sure there is risk to exaggerate here easily…
Once again big thank you for all suggestion and for your time you spent so much here.
Fantastic! I realize that the long posts I write can look like a boring wall of text to people that just want a fast answer to their question. That’s why I’ve enjoyed walking through your audio setup, because you’re actually interested in why and how it works rather than just “tell me what button to push”. There aren’t many audio-centric posts on the forum, so I went a little overboard here for other people’s future reference.
You are correct. There is no voice at 35 Hz, just music. This was mentioned about halfway down the last huge wall of text I wrote lol…
Sometimes, I need to learn that less is more.
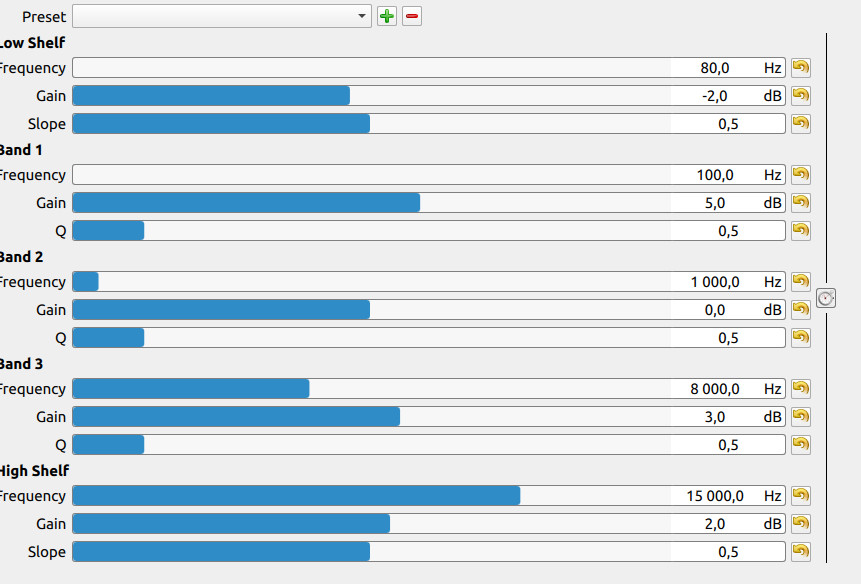
According to your screenshot, Band 2 is sitting at 0 dB. That means it is doing nothing, and is available for use. You could copy the “Band EQ” settings in my previous post directly into Band 2 on your current EQ if desired.
The reduction at 144 Hz is very specific. If we go back to the FFT graph in my previous post, the 144 Hz swell is very narrow before running into the next swell. Reducing EQ at 100 Hz or 200 Hz would be attacking a completely different range of your voice rather than the swell at 144 Hz. Going back to the doubles/octaves relationship, 100 Hz would be almost a half-octave lower than your voice at 144 Hz, which means changing EQ in that range would do little to clean up the interference happening at 144 Hz.
Since you have Band 2 available, it can be configured to reduce 144 Hz by -0.2 dB and you’re done. The other bands do not need to change. After all, I did not change any other bands when I experimented with your YouTube audio, so there’s nothing extra you need to do to replicate my results. I only changed 144 Hz by a small amount to reduce interference.
As for the Low Shelf filter, that one could be applied directly to the music track, since it is specifically attacking the 35 Hz thump in the bass line.
The good news is that nothing drastic like -5 dB at 100 Hz needs to be done. That would be a huge loss of bass, for sure. The change I did was only -0.2 dB on top of your existing settings.
But there’s another way to look at having bass in a voice track. As an example, have you ever listened to an audio book while driving in the car with heavy traffic around you, and the narrator’s voice is all but covered up by road noise? So you raise the volume, but it’s like only a sliver of their voice can cut through the road noise. That sliver of their voice combined with the tinny sound of a car speaker starts to feel like a spike being hammered into your eardrum, and it induces a headache after awhile, right? Interference or distortion in a sound mix can have that same “spike in my eardrum” effect on a listener, even without road noise.
So here’s the consideration… If a particular EQ setting makes for a voice with more bass, but it creates interference in the process, the listener is going to turn down the volume to prevent a headache. The volume turned down by the user will completely defeat any bass boost that was applied, which means the final bass amount that’s actually heard will be lower than hoped. However, if the sound is distortion-free, then the listener can turn their volume up much louder without pain, which will raise the bass with it. Scenario 2 (distortion-free bass) will have louder perceived bass than Scenario 1 (bass with distortion).
That said, the EQ experiment I did on your audio was only a -0.2 dB change on one specific octave. There is plenty of bass left behind.
Sorry I missed that 35Hz is for music… Too many new things… and English is not my native language so it makes it even a bit more complicated…
I’m wondering about the following thing. I don’t do EQ for the whole output, just only for voice. If music is “making problems” what about correcting it at source which means what about adding second EQ just for music track?
If yes, should I set ex. values in EQ for 35 Hz, 71 Hz, 143 Hz and perhaps even for 285 Hz and 550Hz? If yes with what values? -1dB for 35Hz, -0.6 dB for 71 Hz, -0.2 dB for 143 Hz?
AFAIU, you are even partially suggesting that by writing:
But here it’s suggestion only for 35Hz. Don’t you think it would be better to improve music track first? Or should I only “lower” 35 Hz in music track and the rest of correction to do on voice track? or on the whole output?
On the other hand I’m wondering why someone recording the music did “such an error”. Was it done intentionally as this music is a bit specific (“electronic”) or unintentionally?
At the end, how to understand “0.5 slope” and “1.2 Q”? Sure I know that these are parameters but how do they work?
You are correct, the 35 Hz filter can be a separate EQ applied directly to the music track.
Actually, you make a good point… When I ripped your YouTube audio, all that gave me was the combined audio of speech plus music. So when I reduce at 144 Hz, both tracks are affected. Technically, I don’t know if that 144 Hz affected the speech more or the music more, or affected both tracks by the same amount. So, you might be right that 144 Hz needs to be notched from the music, and maybe the speech can be left alone.
What we know for sure is that the highest interference is happening at 144 Hz. As to which track will benefit more from an EQ reduction, well, that would require an experiment on your part since I don’t have your files.
As for the other values above 144 Hz, I don’t see a reason to worry about them. The music track seems to have very little happening in that range, so those will mostly be solo voice frequencies. The other reason I’m not worried about them is because they sounded perfectly fine doing nothing. “If it isn’t broken, there’s nothing to fix.” You’re welcome to try it as an experiment, and maybe it makes a difference. But it would probably be super subtle with this particular song. Now… if using a different song that had more midrange noise in it that competed with your voice? Then yes, notching those higher frequencies in the music track would likely create the “hole in the music” that your voice needs to punch through without competition.
Given the composer, I’m sure it was intentional. These tracks get used for a variety of purposes, including background music for video games. In that context, the thump in the bass is good. If the music was used as background music for a voiceless product demonstration video, the thump would be good there too. But for your very specific voice, there happens to be some overtone overlap. Based on what I’ve seen from Micha’s FFT, his voice would probably not have the same overlap as yours. You just drew the unlucky card in the lottery this time haha. But basically, composers record for the most generic usage purpose. If somebody needs to tweak it, they can easily reduce what they don’t want, like you are doing. It’s easier and more obvious to reduce stuff than it is to add stuff. Adding stuff requires artistic vision. Reducing stuff is just noticing and solving a technical problem.
For the shelves, the slope determines how quick the rolloff happens. The default will probably be fine 99% of the time. Any changes to it would need to be tuned for a specific reason due to a specific sound source, and it takes listening by ear to determine what sounds better and what sounds worse.
For Q… it’s your lucky day! Q will probably get relabeled in the near future to something that suggests “octaves of bandwidth”. This is nice because true Q is a little unintuitive to use. Octaves is easier.
So, let’s use our example of reducing 144 Hz. That’s called the “center frequency”. Then we have another term called “bandwidth” which basically means how wide of a range around the center frequency are we going to affect with this EQ adjustment. With a Q of 1.2 (actually octave once relabeled), that means 144 Hz will see the full effect of the gain adjustment in dB (-0.2 dB in our example), and then the effect of the EQ will taper down to nothing at the 0.6 octave point on each side of the center frequency. Since the human voice has overtones in each octave, I didn’t want to be super wide like 4 octaves because I only wanted to affect the fundamental octave of your voice. There was no significant interference to fix at higher octaves.
Ok man. Thanks a lot. My head is… a bit exploding. I will have to do some experiments and then I will see what is the result. Basing on that either I will delete and upload a new version of video, either it might happen that… I will keep the current one. As I feel a bit uncertain in all that area. In my country we have the expression “better is the enemy of good” and not being expert it’s easy to break sth. But I promise to make some experiments!
Moreover I would try to create some universal way of approaching to my videos (including audio). As otherwise it might happen I will spend to much time on them… In fact that’s already my big problem…
Once again big thank you for all remarks. For sure I’ve learnt many new things even if I’m still beginner in audio processing.



{kind=link}