I will look on that. Thank you. However sometimes it’s good to have some starting point being a base for further modifications. Otherwise it’s easy to go in fully wrong direction…
There are two ways to use a limiter.
Had the threshold (limit) been set to -20 dB instead of -1.5 dB, then the speech track would be loud enough to activate the limiter all the time. This means both the compressor and limiter would be imprinting their “color” on the speech at the same time, making it difficult to know which one to adjust to get a different sound. In this context, using a compressor and limiter at the same time makes no sense.
However, the other way to use a limiter is what’s called a brick-wall limiter. This is what a setting of -1.5 dB does. The limiter only becomes active when the sound is on the verge of clipping. The rest of the time, the limiter is dormant, inactive, sonically transparent. A brick-wall limiter is a last-ditch safety net to prevent clipping. Used this way, it isn’t a volume-level shaping tool like a compressor is. So a compressor and a limiter can be used at the same time without them stepping on each other, since the limiter isn’t active until the sound reaches the danger zone.
Yeah. Tim’s workflow is good for this.
Compressor: When attack and release are super-short like they are in the screenshots, the compressor is effectively being used as a limiter to help suppress clipping. But crushing the front-end of a sound too much can take away the enunciation of each syllable, making speech more difficult to understand. Also, these settings are not very “musical” or natural sounding. Typically, an attack around 25-50ms and a release around 100-250ms can sound more natural on speech, although this is very dependent on a person’s speaking voice and just a guideline. As for the spikes that get past the compressor because of the slower attack time… well, those get stomped by the Limiter on the Output track. That’s what it’s there for. The Compressor is a “musical” tool to get the quality of sound you want, while the Limiter is a “technical” tool to prevent clipping. A single tool cannot do both jobs well at the same time.
Normalize: Two Pass: Why is the speech track still set to -15 LUFS? When the background music is added, is it raising the final volume level by only 1 LUFS? If the music raises the final volume any more than that, the amount of remaining headroom will be so small that clipping becomes very likely to happen.
Limiter: The value is fine, but it doesn’t make sense to put it on the speech track. The goal of putting the Limiter on the Output track is to prevent clipping when speech plus music are combined. If the background music isn’t subject to the Limiter as well, then the background music remains capable of pushing the overall volume level into the clipping zone.
Audio Loudness scope: Those are good-looking numbers! But if “I” of -15.1 LUFS is for speech only, then there’s no room left to add music without raising the volume too high.
It is common for the lead vocals of pop music tracks to have makeup gain of +20 dB or more. If it sounds good, it is good.
That is odd, something doesn’t look right. There is no way it’s your audio going to 764 dBTP. That value cannot even be created by a 48 kHz 24-bit digital audio signal. So ignore it for now. @brian, did something change in the Loudness scope? I thought dBTP used to work before.
Yes it is, and compressors are one of the most difficult audio concepts to master. If there was one and only one video that somebody watched to learn what compressor settings do and sound like (I’m talking about musical/emotional impact rather than meaningless tech jargon and math formulas), then this video by compressor designer Gregory Scott is the video to watch:

@Austin Once again big thank you.
The issue is that now I don’t have any good headphones (my old AKG should be sent to repair center, but despite they are still under warranty, the company given as authorized service center on their website is saying that they are not covered by warranty, I wrote directly to Austria and still waiting for answer, but they have total mess). So I use old Sony ones but with much worse parameters.
Getting to the point, I can’t hear any difference between yours and mine Attack and Release values for Threshold but as you expert here, I will apply yours.
Concerning background music. It’s not very strong. Initially I set Gain/volume for it to -17db but now listening to it, I even decreased to -19db. So with music it adds around 1 to 1.5 LUFS to the total result. It’s not so much.
Sure I will move Limiter to the Output (so it will work for all tracks).
One of my friends recommended me also to cut everything below 70Hz, So I added High Pass filter for speech track with default values and cutoff frequency 70Hz. I put it as second just after Bass and Treble. Not sure if it’s a good idea. Do you have any suggestions here? For my ears it sounds a bit better…
The total result is not bad but the speech is a bit flat. It lacks some deep. When I put volume of my headphones or speakers to very high, it gains a bit more deepness (if I can say like that), but at the normal volume settings it seems to be very flat. Any idea how to improve it? Perhaps its dynamic range is too narrow?
One thing more, I installed shotcut 22.01.17 beta version. In my opinion new EQ works much better than old Bass and Treble filter. However in my case I have impression that my voice sounds much better with +5.9 dB for low and +5.9 dB for high, and I don’t touch Mid (for 3 bands EQ).I’m wondering why old Bass and Treble gives much worse results… Thus perhaps my voice is so much different…
The only think is I’m wondering if EQ should be before or after Compression and Normalize. Before it’s “blocked” agains clipping but gives much worse result. After gives much nicer result to my ears but sometimes sound is close to clipping (audio peak meter becomes red for few ms).
As it’s a bit challenging to discuss without any examples, please let me show to you two pieces improved according to the suggestions above. This seems to be the final version unless you tell that it’s so bad. Please have a look:
without music
with music
What do you think about it? It’s just 40 sec. Please be sure to set full hd resolution to get the best sound quality (there is no video, only sound).
Hmm… I can’t wait few days… 
Well… so you are doing sth completely opposite than me. I added Equalizer 3-Band with Low and High set to +5.9dB. And here using this Equalizer: Parametric you are do sth quite opposite, which means you subtract -12 dB from low and high frequencies. So as I added +5.9 dB you probably subtracted in practice about -6dB (probably not exactly).
I have impression that it’s more the question of taste. I would be curious what other guys think here… I’m not expert here so it might be the case I’m wrong… (otherwise I would not open this thread :D).
Still big thank you for help and suggestion.  And now I have dilemma in what direction to go…
And now I have dilemma in what direction to go…
Here there is some kind of interesting article about “boosting” voice: Blue Microphones
One attempt more. This time no any equalizer, no bass and treble. Just HighPass, Compressor, Normalise Two Pass and Limiter. So it’s more closer to my natural voice.
One one, I hope the last attempt, this time with equalizer: parametric and boosting frequencies around 100Hz, with much smaller modifications in other areas:
A few possibilities here:
-
There is a “gain reduction” meter in the Compressor filter panel. It tells you how much “peak squashing” the filter is doing to the audio. If that meter is fluttering between zero and -3 dB, then there probably isn’t enough compression happening to hear a significant effect at all, and you’re basically hearing the original audio. Which might be fine… if it sounds good without much processing, your work is done.
-
Some voices are naturally smooth enough that these values are not very noticeable. However, people with pronounced "sss"es or that have a lisp will notice a bigger difference in sound as the Attack value changes.
Regardless, I would avoid values less than 10ms for speech simply because that duplicates the work of the limiter, and has potential to reduce enunciation rather than help it.
That’s a great number. This format is also the most useful for describing your sound to other people that don’t have your audio files to study for themselves.
For instance, saying that the Gain filter is set to -17 dB on the music track doesn’t tell us how loud it is compared to the speech track. Gain at -17 dB sounds totally different on a loud rock music track than it does on a quiet solo violin classical music track. Now that you say the music adds 1.5 LUFS to the speech track, I now know that your music is not overpowering your speech, regardless of the type of music it is. I can now sense the volume relationship between the speech and music tracks with the “adds 1.5 LUFS to the final volume” format.
Actually, that’s a good point. Especially if the mic picked up some air conditioner noise in the background.
Generally, the cut filters go first among EQs. For instance, if you do Bass & Treble to ramp up the bass and it happens to ramp up air conditioner noise with it, then doing a 70 Hz cut afterwards is going to cut an already-boosted signal, which at best puts you back to your start point and never actually reduces the air conditioner. The ideal chain cuts unwanted noise first, so that future EQ filters (including Bass & Treble) are altering the signal you care about rather than boosting background noise too.
The “deep” word has come up a few times, and I’m reaching the same conclusion you are about the Bass & Treble filter.
Bass & Treble is designed similar to car stereo systems, where the expectation is that it will be used on music sources. “Bass” in the music world means bass guitars, kick drums, timpani drums, thunder, engine noises, and that kind of stuff. Most human voices are nowhere near the low “E” string of a bass guitar. So most likely, the bass slider on this filter is barely affecting your voice, while the treble slider (designed for cymbals and high strings) is only affecting the upper half of your voice. The actual bass portion of your voice is probably totally neglected by this filter. Human bass-voice is more like a midrange frequency in this filter’s eyes.
My next suggestion would have been to try the 15-band EQ or parametric EQ in the beta version of Shotcut, which you already did. I think you’ll get much better and more customizable results with those filters.
There is relentless debate about whether EQ should come before or after compression in the analog world, and there are cases for both. However, in the digital world with Shotcut where clipping must be avoided at all costs, the chain is pretty well-defined:
Compressor → Normalize → Low Cut/High Pass → Additional EQ
or, for sources with noticeable background noise in them…
Low Cut/High Pass → Compressor → Normalize → Additional EQ
If Normalize came before Compressor, then it may send spikes over 0 dB and cause clipping before the Compressor can pull the spikes down. That clipped information would be irretrievably lost and damage the audio.
Similarly, if EQ came before Normalize, then the EQ settings made at the quieter volume level would get ruined by the Fletcher-Munson Curve and have to be redone for the new volume level.
Of all the samples in this thread, I liked your first one the most:
https://www.youtube.com/watch?v=4IRVIRp_b2w
Maybe if the EQ bass boost was reduced by 1.5ish dB, it would be perfect. I think it sounds great as is, but it’s very punchy. For a short commercial, that’s perfect. If I were listening to a 10-minute video with that amount of punchiness, I may develop a little ear fatigue, hence the slight 1-2 dB drop of the bass recommended for longer videos.
EDIT: A key difference here is that I’m listening to your audio on external monitors, Dynaudio BM5A, at a pretty healthy volume level. These speakers, while certainly not the best or biggest in the world, are still able to reproduce much stronger (and more accurate) bass frequencies than your headphones will. Making EQ decisions with headphones is very difficult for this reason. The audio may have more bass than you realize because your headphones physically can’t reproduce how much is in there. If you have some external speakers, I’d recommend checking EQ with them too and finding a happy medium between them and the headphones.
Okay, looks like you posted again as I was writing this. Your latest version with parametric EQ sounds excellent as well, and I could easily listen to that for an extended period of time. Referring to this video: https://www.youtube.com/watch?v=ayLQR2ahrK4 Also noticing that you used Low Shelf in the parametric EQ, which means you may not need to duplicate that functionality with a separate High Pass filter at 70 Hz anymore like we talked about a few paragraphs above.
I think you’ve found the magic zone where you can get any result you want with minor variations to your settings, and all of them will sound good. Well done! Perseverance paid off!
The “True Peak” calculation is based on a 2x oversampling of the audio. Very large values are possible as an “overshoot” when there is a large “impulse” signal. I think I have seen large numbers like that in some torture testing I did early on in the development of the meter.
It is highly interesting to follow your discussion. I can learn a lot there.
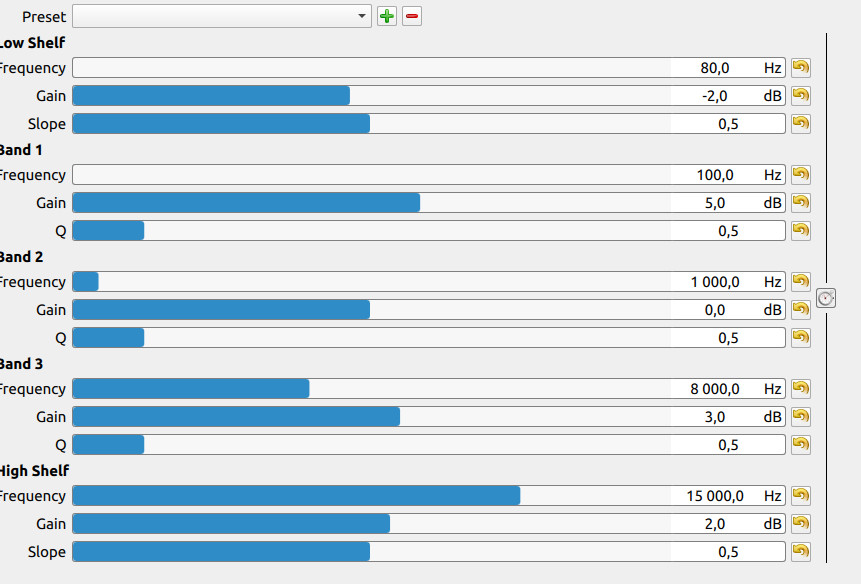
On this version: VER C (audio only voice4 with eq equalizer) I see that at 15,000 Hz the gain is + 2dB. What’s the point of boosting this frequency if there is no human voice at all in this range?
And why is there only a -2 dB cut in the low shelf at 80 Hz, isn’t that just unnecessary noise and no voice frequencies anyway?
Once again big thank you.
I’m only wondering about this order. As I initially did: High Pass - Equalizer: Parametric - Compressor - Normalise: Two Pass.
I’m writing now being a bit in hurry so I will do some testing later. However I’m wondering about the following thing. If Compressor and Normalize have the intention to put my voice into some kind of range in order not go go outside this range and then if I add equalizer later, it might happen theoretically (or am I wrong?) that my voice go outside the range? If equalizer is before thenn compressor and normalize given later somehow guarantee that it’s kept in the range… Is that not the correct understanding?
I was also wondering how to eliminate better breathing sound. In some moments I can still hear it.
Probably I will continue with VER C (audio only voice4 with eq equalizer) - YouTube with perhaps some minor modifications… The idea is to listen it for longer time, not just few seconds. So it has not to be nice for ears for longer time.
The problem is that I don’t have any good speakers. But I will try to listen it once again with the ones I have and if I have impression that bass boost is too high, it might happen I will slightly reduce it.
Well, I followed a bit this article about setting values for voice track the link I’ve given earlier. However for equaliser we don’t put the range like between 100 and 200 Hz you have to add ex. +5dB. Instead it’s more “plastic” and you set 150 Hz as +5dB. Moreover I wanted to give some boost around 100 - 200 Hz so for 100Hz I have +5dB. I’m wondering if it would be better to set 150Hz instead of 100Hz as first parameter.
For 80Hz it’s only -2dB as firstly I have High Pass Filter first so in practice below 70 Hz I have almost nothing (depending how good this filter works, it’s probably never 100% perfect), but around 100 Hz I give 6 dB thus giving for 80Hz ex. - 20 dB I would somehow kill the values for 100Hz. It would be some sharp “shape”.
At least it was my understanding… It could happen that wrong…
Concerning 15000 Hz, it’s rather the question for area between 8000 - 10000 Hz… Here I want to have some smaller boost with values slowly being reduced from 8000 Hz when we go up… so I expect that ex. for 10000 Hz with such a setting I would get ex. 2.5 dB or something… But again I might be again wrong…
Hello @Austin,
I haven’t read such a deep, constructive, educational, valuable and understandable discussion even once on the Kdenlive forum. Audio is almost never discussed there, much to my frustration.
If so factual and constructive is spoken here, I assume that it will not be long, and then Shotcut is the No. 1!
But, Austin, please explain to me if the human voice can be heard at all below 80 Hz and above 10,000 Hz. And if not, as I thought, then surely in the low shelf and high shelf you’d better cut off those ranges completely to reduce any unwanted signals. Or am I wrong?
So my question would be, is there a reasonable setting for low and high self, for spoken voice.
2 Likes
Again, this is a quality in Shotcut that I sorely miss in the other video editors for Linux. A compressor without this display is like flying blind.
1 Like
Technically, this can work and produce equivalent results. But there’s an efficiency caveat.
First, you bring up the excellent point that the order of the filters in Shotcut does not necessarily have to be the same order that their parameters are configured. For instance:
Filter order in Shotcut filter panel:
Low Cut/High Pass → Parametric EQ → Compressor → Normalize: Two Pass
Order that filters are configured:
Low Cut/High Pass → Compressor → Normalize: Two Pass → Parametric EQ
Using this sequence, you are correct that any boosts made by the EQ filter would get controlled by the Compressor and be less likely to clip. True point.
Note that Parametric EQ is still configured last because it’s inefficient (a waste of time) to configure it before Normalize, only to configure it again after Normalize due to the perception differences of being at a different volume level.
This brings us to the caveat. In the filter sequence above, any changes made to the EQ filter are going to cause volume changes that affect the threshold and makeup gain of the compressor. That means changing the EQ now requires the Compressor to be updated to reflect the new incoming volume level. Depending on what the Compressor is doing, a change might need to be rippled to Normalize as well.
The basic issue is that the EQ filter will likely be the filter that changes the most as you hunt for your perfect sound. The more likely a filter is to change, the nicer it is to put it at the end of the chain. If EQ is last, you can alter it all day long without having to go back and update the Compressor or Normalize filters to compensate for the new EQ values.
So, I personally use Low Cut/High Pass → Compressor → Normalize: Two Pass → Additional EQ from the perspectives of both highest audio quality and most efficient workflow (least amount of rippled rework). It is not the only way to do things, of course. But it’s efficient and effective on many sources.
You also made a good point about the potential of a big EQ boost to cause clipping if EQ is done last. Yes, technically, this is a possibility. However, this is also why YouTube and other platforms set their LUFS targets between -14 and -16 LUFS. Broadcast television goes as low as -23 LUFS, and cinema goes even lower. These targets mean you’re allowed to have significant headroom before clipping without being perceived as quieter than everyone else’s audio. As in, if there is an audio track whose average volume level is -14 LUFS, and an EQ change causes that track to clip, then something alarming has just happened with that EQ:
-
That audio track may have crazy wide dynamic range that needs to be shrunk.
-
That EQ change may have been ridiculously drastic. If a source has to be altered by more than 10 dB of EQ, then either the microphone is not capturing the sound they want at all in the first place, or they’re trying to stretch the sound into something totally foreign, like doing sound effects work to create alien voices.
Generally speaking, normal EQ changes will not be drastic enough to overrun -14 LUFS of headroom. That’s what the headroom is there for… room to play. Even if EQ does cause a drastic enough change that clipping happens, all that needs to be done is go back to the Normalize filter and drop it a few dB. (Watching the “I” loudness meter can provide an exact number.) Now the boosted EQ will fit inside the additional headroom we just freed up. That’s a much simpler change than having to redo the Compressor threshold to account for the boosted EQ coming into it. Nobody wants to tweak a compressor any longer than they absolutely have to. That thing is complicated and touchy. ![]()
Good call. Personally, for speech, I like the Low Cut/High Pass rolloff filters because they drop volume all the way to minus infinity instead of just shelving (stopping) at a certain volume. The infinity rolloff will block more low-rumble background noise than a shelf will. Granted, for non-solo musical sources, a shelf can often sound better than an infinity rolloff.
This is usually done with a half-billion quick fade-ins and fade-outs at clip split points where breathing happens. Or with keyframed volume ducking. It’s ugly.
Sometimes, a Gate filter can detect that your voice volume dropped to nearly nothing and close the sound down so that breathing isn’t enough to trip the gate and get through. However, a lot of pro timelines still use fade-in/fade-out because it’s manual and fully controlled. As in, a Gate kinda does whatever it wants based on the incoming sound. If you’re still tweaking your sound and changing volume levels, then those changes will mess with your gate settings too. The only way to know if the Gate is responding properly is to listen to the entire track in real-time to verify it’s right. And then you can’t modify the volume settings anymore without risk of messing up a working Gate. Pros don’t have time for a full-track manual review, and can’t sacrifice their editing flexibility. So they often stick with the ugly but reliable fade-in/fade-out method.
That said, if your audio is super constant and clean, you might be able to get away with a gate filter.
On VER C, it was comfortable enough on my speakers that the bass could maybe even be boosted ever so slightly. It didn’t have the punch and presence that VER A did. So, removing even more bass might make it too weak to compete with background music. Just my thoughts based on external speakers.
If it sounds better, then yes. If it doesn’t, then no. This is the only iron-clad rule of audio engineering. ![]()
Generally no to both. There are some voiceover guys with massive voices that can dip slightly into 80 Hz, but the fundamental for mere mortal guys is higher. If somebody did a Low Cut/High Pass at 70 Hz, they would probably be solid for 100% of humanity. (I like how “probably” and “solid” and “100%” are in the same sentence. Only a Sith deals in absolutes.)
Also for speech, there is generally nothing of interest above 10 kHz. It will mostly (if anything) be the hiss that results from sharp “sss” words. Few people need more “sss” in their speech. The meat of sibilance is around 5-6 kHz, so I could imagine some EQ control being done in that range.
To your point, yes, it makes sense to roll off everything below and above that range to reduce stray noises. A High Shelving filter from the parametric EQ is probably sufficient for the 10+ kHz stuff rather than a dedicated High Cut filter, since there is unlikely to be any significant noise there in a halfway-decent room. Air conditioners don’t hang out in that higher range, for instance.
2 Likes
Hello @Austin,
I can’t believe it!!! So much quality! Content! Real help, even if it requires a lot of thinking. It makes me very thoughtful. If you think I’m exaggerating - check out the other video editor forums.
And there is one more important tool that can only be found in Shotcut: “Audio Laudness”.
It’s your own fault if I switch to Shotcut!!!
I would like to ask a question to the developers:
What is your intention, your goal for Shotcut?
Is Shotuct mainly a Linux program?
You can always read on the Internet that Linux is good, but that it has nothing satisfactory to offer for video editing.
I have the impression that you have set out to turn this prejudice completely on its head.
If I can help Shotcut and you do that - I’d love to be there.
1 Like
This is the highest compliment I can hope for. ![]()
1 Like