That’s a very reasonable value. (EDIT: After seeing your screenshots… maybe not. Skip to the very last paragraph for the short version.)
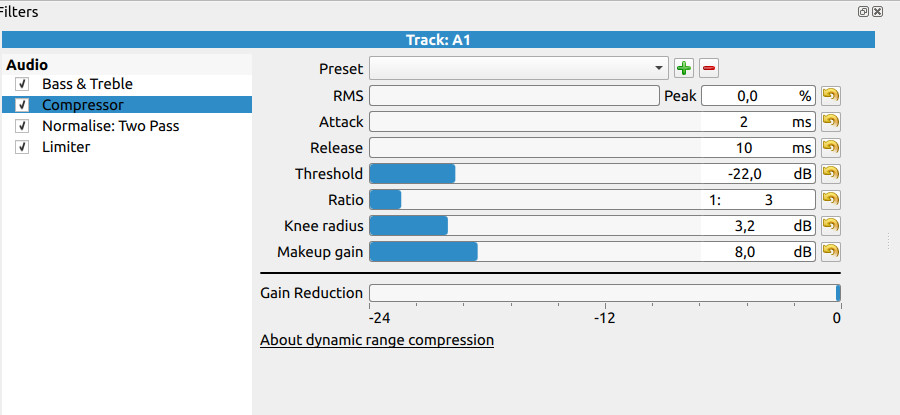
There are two possibilities. One is that the original voice recording has a very wide dynamic range. This can happen when speaking very close to a sensitive microphone. The analog fix is to get a less sensitive microphone, or speak from a further distance away. The digital fix is to add a Compressor filter before the Normalize filter. The Compressor will reduce the dynamic range so that the loud spiky parts of the waveform will not go above 0 dB when everything is raised by the Normalize filter.
To answer your other question about how the Normalize filter works… yes, it’s very simple. It analyzes the audio, determines the average loudness, and adds Gain to the entire track. As in, if the average loudness is -20 LUFS and your target is -15, then it adds +5 dB of Gain to the entire track. This amount of gain could be pushing spikes through the 0 dB ceiling, causing clipping and the buzzing noise. The Compressor will shrink the spikes before Normalize gain is applied. Adding the Compressor after Normalize is too late… the spikes have already gone over 0 dB and that information is lost.
The other possibility is that the sound levels are hitting 0 dB because the sum of your speech track plus music track together results in a spike that’s too loud. Maybe lowering the music volume or putting an EQ notch in it will prevent the sum from being so loud.
The sure way to know is to mute the music track and see if the audio still spikes. If it does, then you know the speech track on its own is too loud and it needs a Compressor. But if speech is fine by itself, then you know the music is too loud. If you’re unable to add music to speech at a decent level without clipping, then the speech needs a Compressor added to free up some headroom for the music to fill.
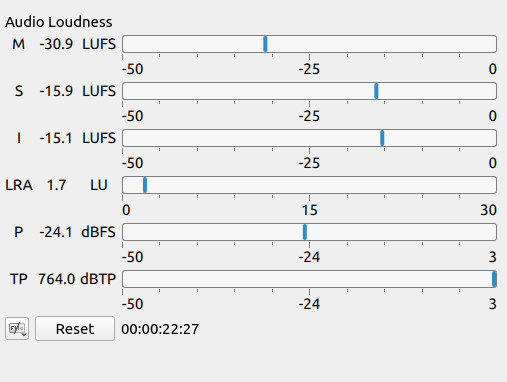
Just saw your screenshots.
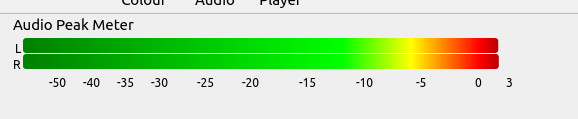
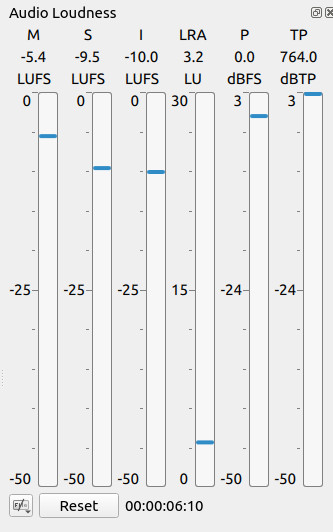
764.0 dBTP?? I’ve never seen it go that high. I think you set a record!
So, this screenshot is telling me some things. First, the “I” meter is the Integrated (average) volume over time, and it’s showing -10 instead of -15. So I assume I’m looking at speech plus music here, and that music has raised the volume level by 5 LUFS. That’s huge, and definitely a problem.
So we first need to figure out why the “I” meter is at -10 instead of -15. Has something changed on the speech tracks and they need the Normalize: Two Pass > Analyze button hit again to update their internal gain setting? Was the Reset button hit in the Loudness Meter section to zero the meters before playing back a section, so we’re seeing a true measurement instead of a hodge-podge average of random playback points? The LRA (loudness range) has me concerned too… it’s pretty small, similar to commercial music tracks, which has me wondering if the background music is simply too loud.
Regardless, here’s our basic problem… despite Normalize: Two Pass being set to a reasonable value of -15 LUFS, the final volume level is actually -10 LUFS, which will have a very high probability of spiking to 0 dBFS. We need to find some combination of filter gain values or clip re-analysis that will get the “I” meter back down to -15 LUFS.
It is common for background music to add 2-3 dB of volume to a speech track. This means that if you want your final volume to be -15 LUFS, then set the Normalize: Two Pass filter on the speech track to be -18 LUFS instead of -15 LUFS. Speech at -18 LUFS plus music that raises the volume by 3 LUFS will put the final volume at -15 LUFS, which should be enough headroom to avoid clipping.