Hello, I wonder if it would be possible to incorporate the kokorodoki text to speech to Shotcut, it has many different voices very human alike and different languages as well.
I’m making video(audio) book, and it would be easier and faster to have all in one in shotcut.
We already have a wonderful STT (Speech To Text) in Shotcut, the circle would be closed with a TTS
We are moving away from bundling heavy things like this that create a burden for maintaining builds and increase download and install size. People can install this on their own and work with that project to make it easier to install.
I see it has a command line tool that accepts a text string or file. However, it does not support timed text such that you can export subtitles to control its timing. Instead, we might be able to add a menu function that creates a bunch of jobs–one for each subtitle item–and then places the generated audio on an audio track at the correct time. What do you think about that?
If I understood… It would put the audio at the exact line of subtitle, for each line it will cut the audio to put it where it needs to be?
If it can do a whole 1 hour or 2 hours audio in automated way, I think it will be excellent. If it’s what I understood…
On the other hand, I would prefer that Shotcut takes the original text (the story in pure txt like copy past to Pluma) and parse it/time it, in a way I can export as .srt, actually it’s shotcut which extract the audio and then transcribe the text and timing, thus there are a lot of error, even with the heavy 1.5GB Speech to text I did selected/downloaded in shotcut, being able to parse the original text would be a plus
In all case thank you for answering, for Shotcut, and please have a fantastic day.
That seems like a different request but not too unreasonable. An interesting idea. My first thought is… that depends on how one chooses to speak and their understanding of when to slightly pause, etc. As you point out, it would not be reliable to use text-to-speech and then speech-to-text on that even though it would help with that timing. A general problem with the request is that it is unrelated to whatever is happening in the video. In that case, the value is to get a bunch of subtitle items whose timing you can manually adjust. I suppose there is some simpler tool that can break up a long text into phrases, calculate some rough timing per phrase, etc. I think you could try to ask any chat AI to do that. Like this:
Break up the following paragraph of text into a series of timed phrases and generate the subtitle SRT for it:
1
00:00:00,000 --> 00:00:03,800
That seems like a different request, but not too unreasonable.
2
00:00:04,100 --> 00:00:05,400
An interesting idea.
3
00:00:05,700 --> 00:00:08,700
My first thought is that it depends on how one chooses to speak,
4
00:00:08,700 --> 00:00:11,500
and their understanding of when to slightly pause, etc.
5
00:00:11,800 --> 00:00:16,700
As you point out, it would not be reliable to use text-to-speech and then speech-to-text on that,
6
00:00:16,700 --> 00:00:18,500
even though it would help with that timing.
7
00:00:18,900 --> 00:00:23,100
A general problem with the request is that it is unrelated to whatever is happening in the video.
8
00:00:23,500 --> 00:00:26,900
In that case, the value is to get a bunch of subtitle items
9
00:00:26,900 --> 00:00:29,200
whose timing you can manually adjust.
10
00:00:29,600 --> 00:00:33,000
I suppose there is some simpler tool that can break up a long text into phrases,
11
00:00:33,000 --> 00:00:34,800
calculate some rough timing per phrase, etc.
12
00:00:35,100 --> 00:00:37,200
I think you could try to ask any chat AI to do that.
I was able to build a docker image that contains this. That probably does not mean much to you, but there is always the question: how are you going to get and run this new software that is somewhat complicated to manually setup and install? Docker is a cross-platform solution. It has an installer and is in all Linux distro repositories. I can tell people to get Docker and download the kokorodoki image. Then, Shotcut can drive it similar to how it drives other executables.
P.S. The docker image is 17.8GB! At least it contains the models.
I will always find a place for it on my drive if it means I can do it locally instead of depending on websites (which actually I depend on and it’s quite a pain).
Can I try/download your “docker”? If so do I need some instructions?
In all case, I’m speechless about your kindness, Thank you so very much for all you did. Please have an absolute wonderful day.
Today, I added reading and processing .SRT to kokorodoki. This produces one audio output file much faster than one per subtitle line. Here is an example made with the SRT above:
It is not perfect. I might need to still include the ability to convert a single subtitle item to amend the imperfections in the generated audio. Or, maybe the problem is that the lines are too long for the start time plus speed. kokorodoki does have a speed option. Here I ran it with speed 1.5 instead of the default 1.2:
Here is how to run it (it downloads automatically):
docker run -it --rm -v $PWD:/mnt -w /mnt mltframework/kokorodoki:25.08.09 -f example.srt -s 1.5 -o interesting.wav
This is not using /mnt on your system; that is the working directory inside the container. This is mapping the current working directory ($PWD) on your system into the container. Notice I did not specify a path to example.srt. That is expected in your current directory, and it will write the output WAV also to the current directory.
Thank you for your patience and making this text to speech
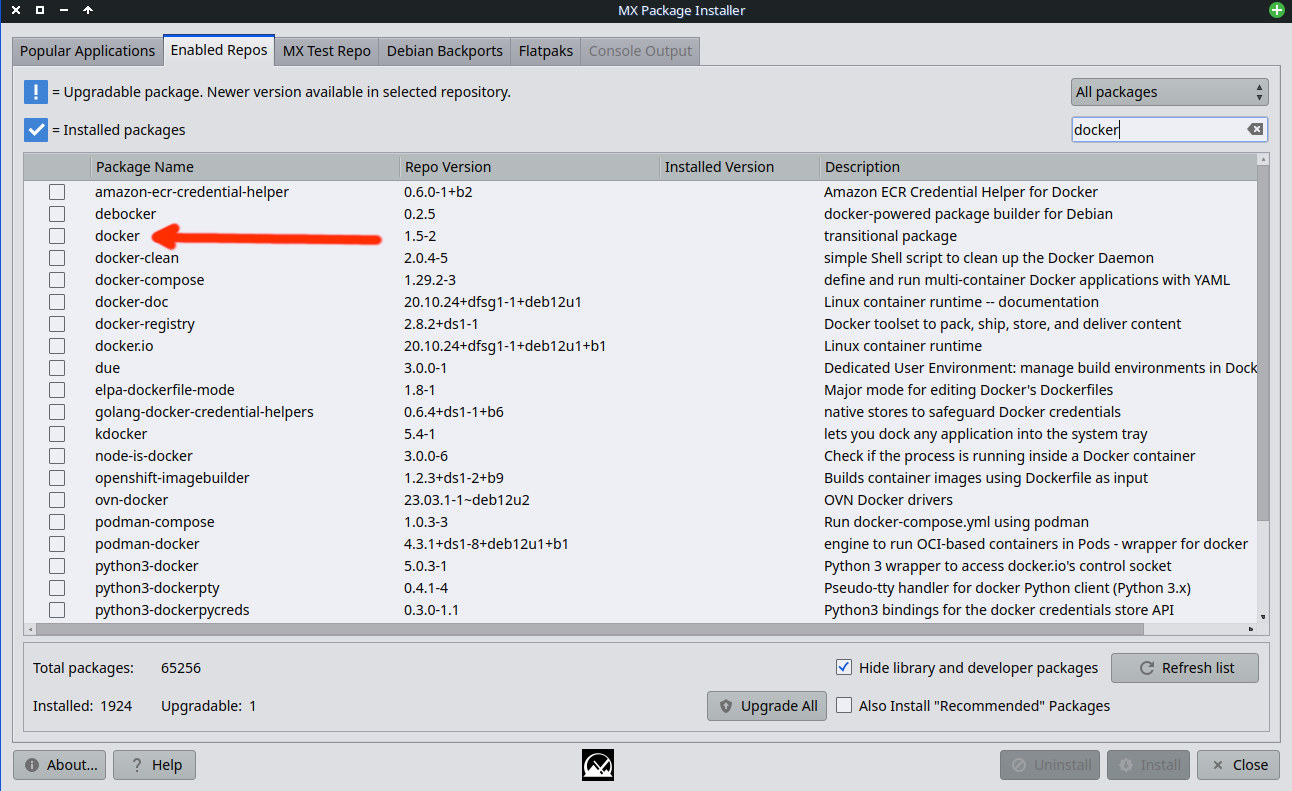
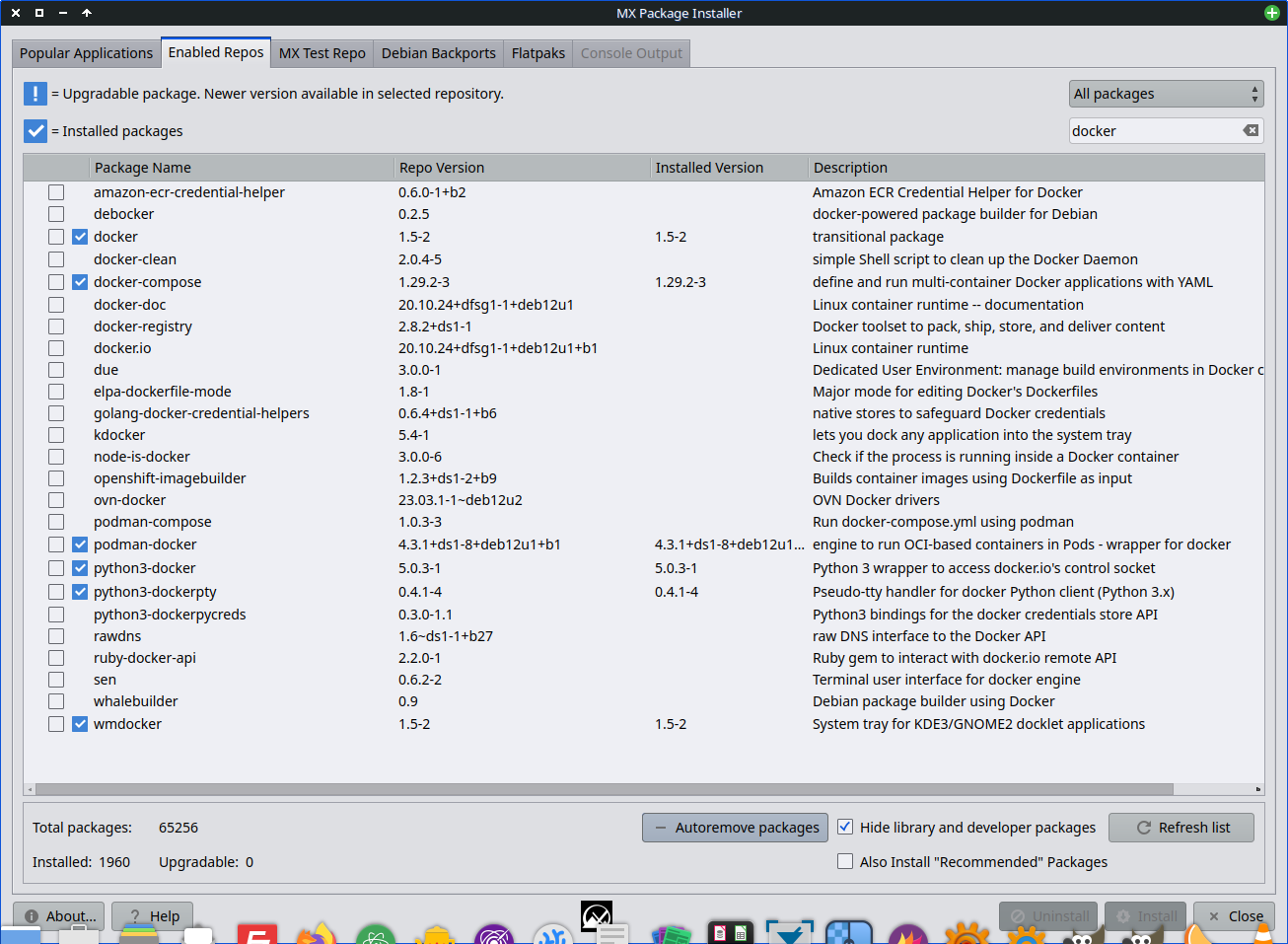
So I did installed docker (the one in my previews screenshot)
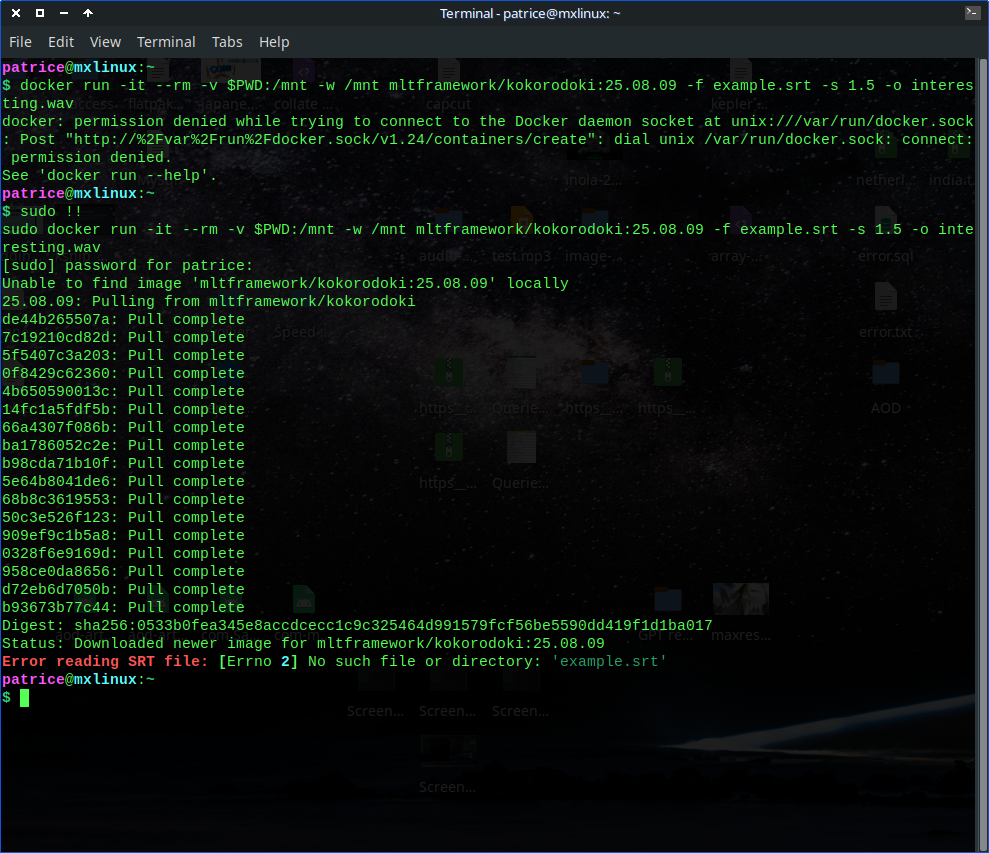
Sadly this is where problems start for me
patrice@mxlinux:~
$ docker run -it --rm -v $PWD:/mnt -w /mnt mltframework/kokorodoki:25.08.09 -f example.srt -s 1.5 -o interesting.wav
Command 'docker' not found, but can be installed with:
sudo apt install docker.io
sudo apt install podman-docker
After installing those two dockers terminal did ask me, I re-run the command
Strangely when I installed podman-docker it removed docker.io …
patrice@mxlinux:~
$ docker run -it --rm -v $PWD:/mnt -w /mnt mltframework/kokorodoki:25.08.09 -f example.srt -s 1.5 -o interesting.wav
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
WARN[0000] "/" is not a shared mount, this could cause issues or missing mounts with rootless containers
Error: short-name "mltframework/kokorodoki:25.08.09" did not resolve to an alias and no unqualified-search registries are defined in "/etc/containers/registries.conf"
patrice@mxlinux:~
$
And… I got this error, and no download
What did I do wrong?
I put a screen shot about the all dockers my distro auto-installed as needed packages beside what I asked to install. (docker.io is not anymore installed as removed by podman-docker)
In all cases I don’t want to take your time, if you feel it will take too much time to solve it, better to tell and give up
Good to know > I’m the opposite of a champion with terminal
Thank you so very much for your patience and trials, please have a fantastic day.
podman is messing things up and is not compatible. I think the two install commands it gave you were two different options to choose from, and you should only use docker.io
I still got an error, I know I did not put any srt file, but I don’t know where to put it
Thus a question, where is the directory I need to put a srt file? also what do I do from there/now?
Thanks a lot for your patience, please have a tremendous day.
This. You need a SRT. Shotcut can export one from subtitles. AI can generate one as I showed above. If you still have trouble you need to wait until I release this.
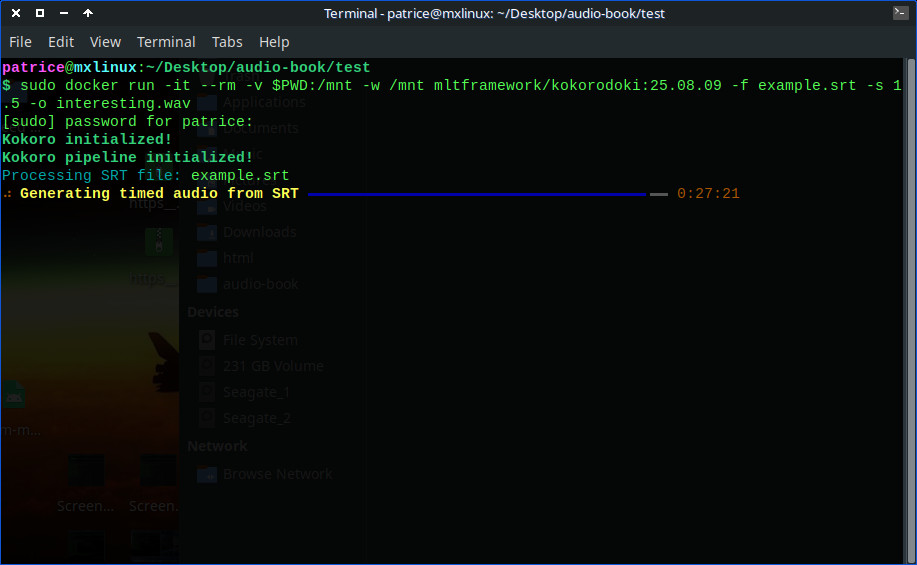
So Finally it worked
Question, can we chose the voice type, the talking speed?
Let’s start my experience:
Stupid enough I did not check the length of my srt ( a 1-hour+ story), so on my old computer it took 30 minutes to do the job (old i5-7400 cpu), but I’m very ok with that .
Another thing, and this one scares me now… is the cores’ temperature, not sure I’ll do it again especially if the process takes more than 10 minutes.
With burst peaks at 94/95 C (in yellow rectangle on the screenshot), I was scared to see some smokes appear thru the transparent side of my PC and just hoped for the best
The Result:
Not what I expected… at all (I’m very sorry to say it)
I can’t understand what she’s saying (yep it’s in English ), way too fast, way too choppy, even in Audacity slowing down to a “normal” pace, it does not look natural.
In the end, not sure where to go from here, if we can chose the voice, just hear some sampled voice (a bit like in Audacity before applying a filter) from Shotcut, chose the tempo/pitch, it can be useful for some people, but to narrate stories/novels, it’s too choppy (maybe just add a button to get the TTS without passing by the srt, but a txt file, the first purpose of kokorodi?).
If you want me to do some more tests with something you have in mind, please it will be my absolute pleasure to try it and give you feed-backs.
How do you delete the 15GB of installed files? (Just to know, I’ll keep for the moment, but I would like to know how to delete all what docker has installed in first place)
In all case thank you so much your time and patience, I very much appreciated it, please have an absolute fantastic day.
For the passers-by reading this, you need to open terminal from the folder you have your SRT, then put the command line, don’t lose your time, like me, searching where is the folder “mltframework”
Also no space in the folder name or your will have an error… learning it the “hardway”
You can choose a voice. It is in the Kokorodoki README GitHub page you linked to a the beginning of the thread. It was a not a good idea to choose something over an hour long for your first test. I cannot do anything about the CPU usage, but you can ask Kokorodoki project for an option to use less threads. There are a lot of things you can do in a video editor that will consume most of your CPU usage for long periods of time. Just look around here more.
As for the quality, it is choppy because of the way your SRT is structured. Either the start time and duration of items need to be stretched out more, or you have to make kokorodoki talk faster. There is an option for speed. To deal with a space in the path, you need to put quotes around "$PWD". Most of these are things that are going to be done in an integration with a UI. Also, you could skip using SRT and just give it a text file. Again, there is a kokorodoki command line option for that. Then, you can edit the audio file as needed. I will think about a way to offer that in the UI such as the Notes panel context menu.
You can search the Web for that. Basically docker rmi but you need the image identifier, which you get using docker images.
Update on this. I was able to reduce the docker image size to 13.2 GB, and I added a latest tag to it. So, simply pull mltframework/kokorodoki to get the latest.
I also started the integration into Shotcut for the next version.