26 seconds! - Yowzaaah!
This morning I saw that I now have 21.01, so I did the speed tests, as promised.
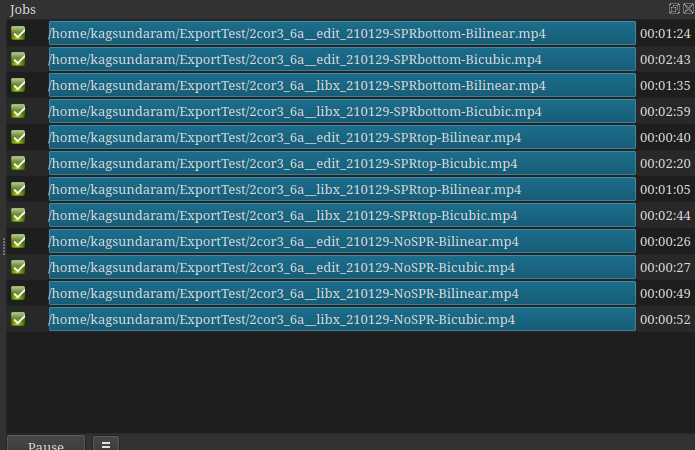
(“edit” runs are the H264 NVENC codec with GPU enabled, “libx” are libx254 codec with no GPU)
With the Size, Posoition, Rotate filter in the way, there is little or no difference.
When the SPR is taken out of the way, Shotcut 21.01 screams, cutting 35% off of the Export time.
@shotcut, we can say… It works!